InfluxDB
時序性資料庫。拿來監看 Metric 還不錯!
Time Series Data
資料量非常大 (1000 nodes 每 10s 回傳 10 個 measurement)
定時資料/不定時資料(事件觸發)
例:股市, Metrics, Events, Sensor Data
Time Series Database
寫快(隨時有大量資料寫入)
讀快(通常用於 觀察/分析/預測 新資料)
壓縮(資料量很可觀)
很少刪除個別資料(同 serie)
大量刪除很快(同 serie)
Time Series Database(Influxdb)
寫快: WAL (Write Ahead Log)
讀快: 以 {series_id, timestamp} 方式讀取
壓縮: 針對不同資料格式進行壓縮(snappy, double delta…)
RollUp and aggregate
Retention Policy(資料保留時間)
Continuous Query(定期 aggregate 資料)
SQL style query language
Influxdb Schema
- Measurement (CPU, 溫度…)
- Tags (region=uswest host=serverA sensor=23), Indexed
- Fields (溫度=20 濕度=30)
- TimeStamp nanosecond
Measurement:Sensor Data
| \ | Tag:region | Tag:sensor | series_id | timestamp | Field:溫度 | Field:濕度 |
|---|---|---|---|---|---|---|
| point 1 | 美西 | 23 | 1 | 1 | 12 | 34 |
| point 2 | 美西 | 23 | 1 | 2 | 12 | 34 |
| point 3 | 美西 | 23 | 1 | 3 | 12 | 34 |
| point 4 | 美西 | 23 | 1 | 4 | 12 | 34 |
| point 5 | 美東 | 24 | 2 | 1 | 12 | 34 |
| point 6 | 美東 | 24 | 2 | 2 | 12 | 34 |
| point 7 | 美東 | 24 | 2 | 3 | 12 | 34 |
| point 8 | 美東 | 24 | 2 | 4 | 12 | 34 |
| point 9 | 美東 | 24 | 2 | 5 | 12 | 34 |
| point 10 | 美東 | 29 | 3 | 1 | 12 | 34 |
| point 11 | 美東 | 29 | 3 | 2 | 12 | 34 |
| point 12 | 美東 | 29 | 3 | 3 | 12 | 34 |
| point 13 | 美東 | 29 | 3 | 4 | 12 | 34 |
Story
目標:
- Billions of individual data points
- High write throughput
- High read throughput
- Large deletes to free up disk space
- Mostly an insert/append workload, very few updates
LSM Tree -> B+ Tree -> TSM Tree
LevelDB and Log Structured Merge Trees : 太多分散小檔案
BoltDB and mmap B+Trees : 單一檔案達幾 GB 產生 spiking IOPS
Time Structured Merge Tree : 類 LSM Tree
Data File
| Magic Number | Data Block 1 | Data Block N | Index Block | min time | max time | series count |
|---|---|---|---|---|---|---|
| 4B | … | … | … | 8B | 8B | 4B |
Data Block
| Series ID | Length | minimum timestamp | Compress block |
|---|---|---|---|
| 8B uint64 | 4B uint32 | 8B | … |
Index Block
| Series ID Nth | starting position |
|---|---|
| 8B | 4B |
Libs
- Go
- Haskell
- Java
- JS/Node
- Lisp
- …
TICK
- T Telegraf
- I InfluxDB
- C Chronograf
- K Kapacitor
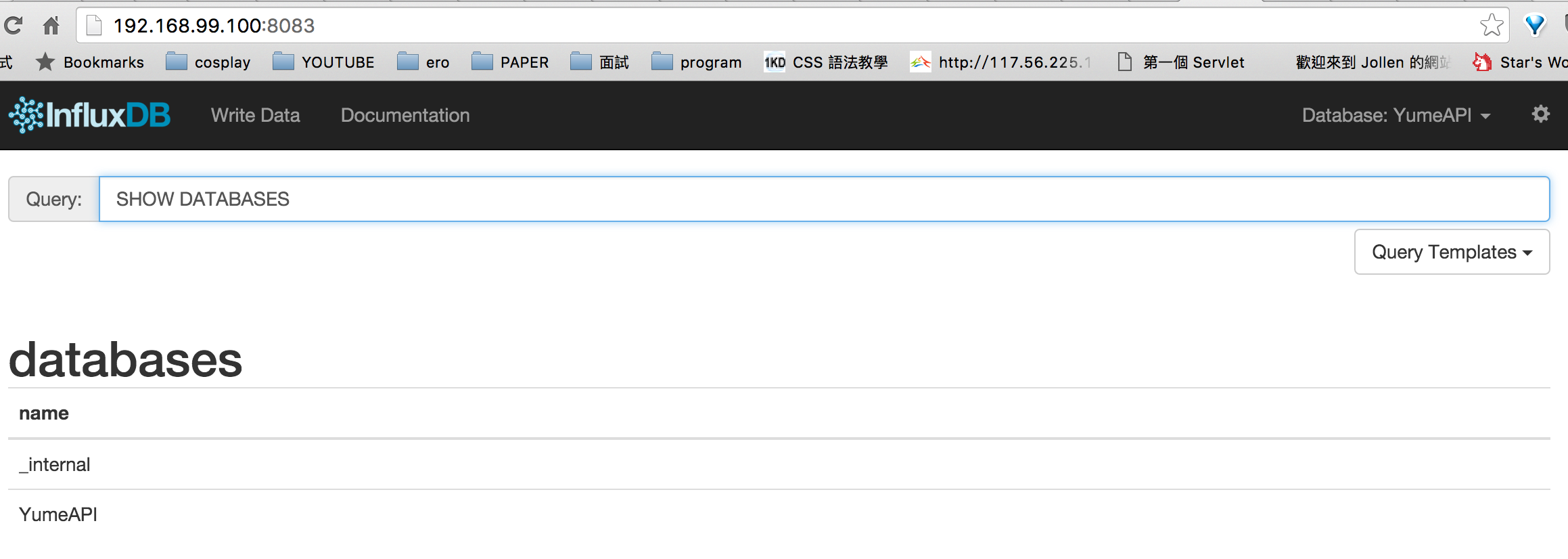
安裝 InfluxDB
Pic

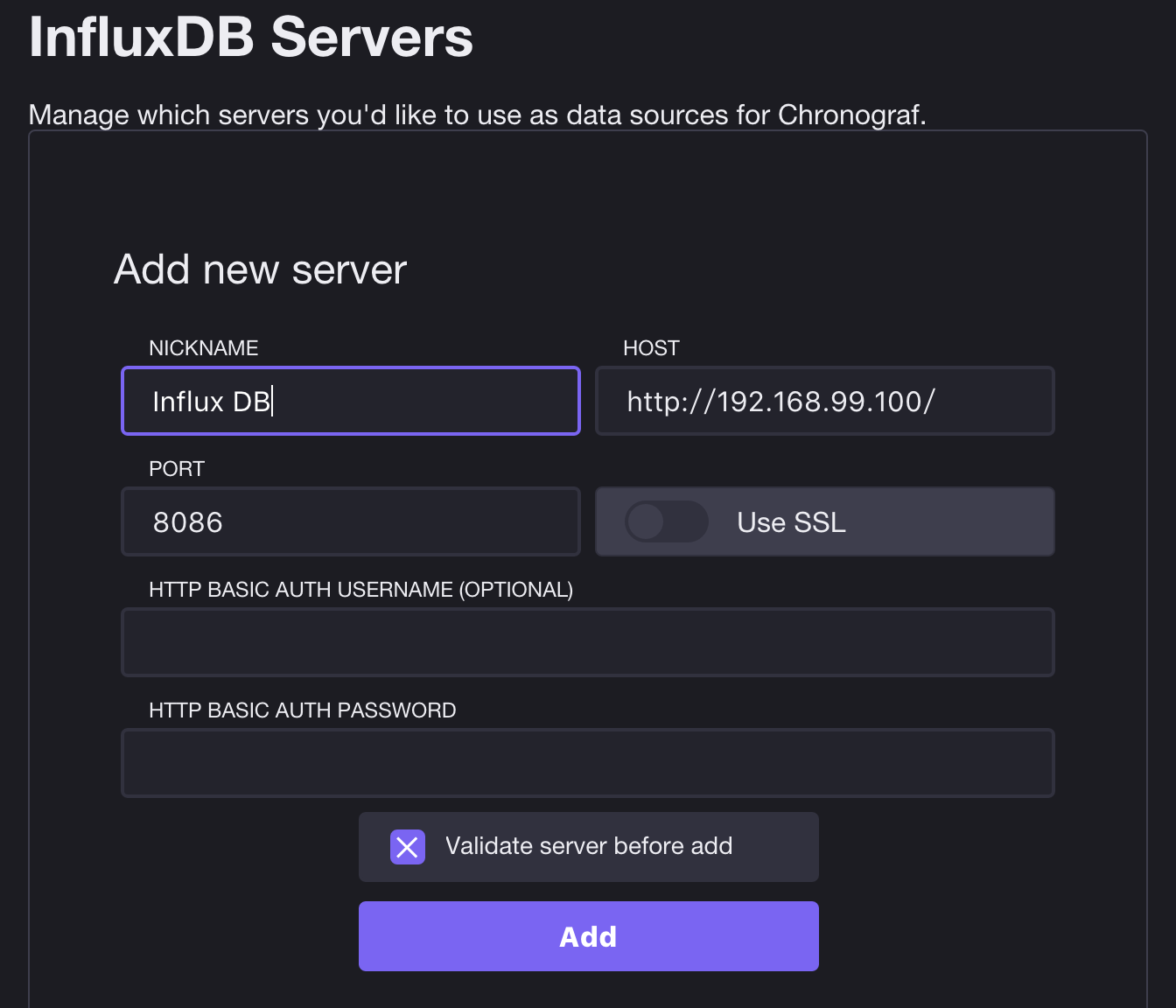
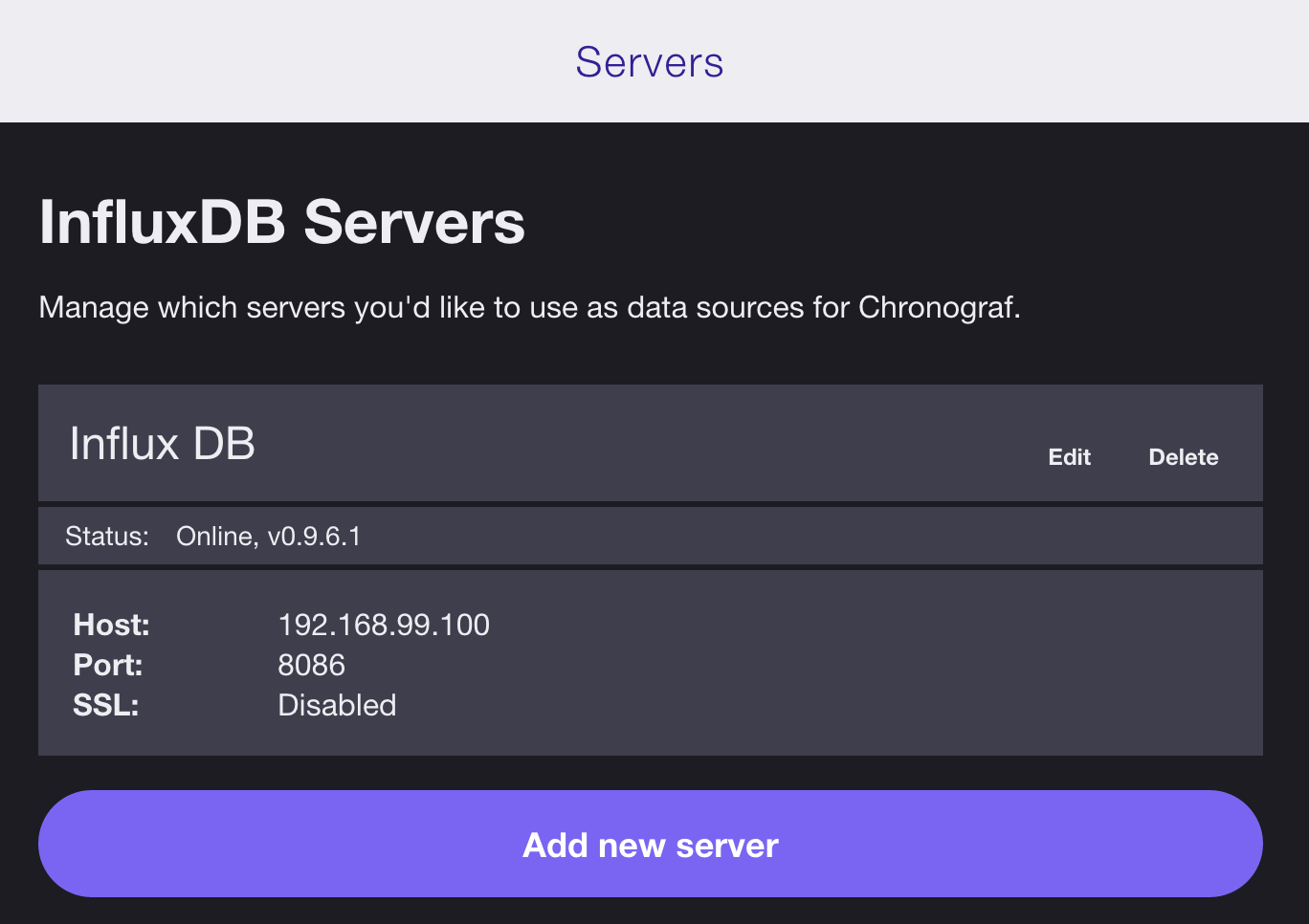
安裝 chronograf
chronograf 設定
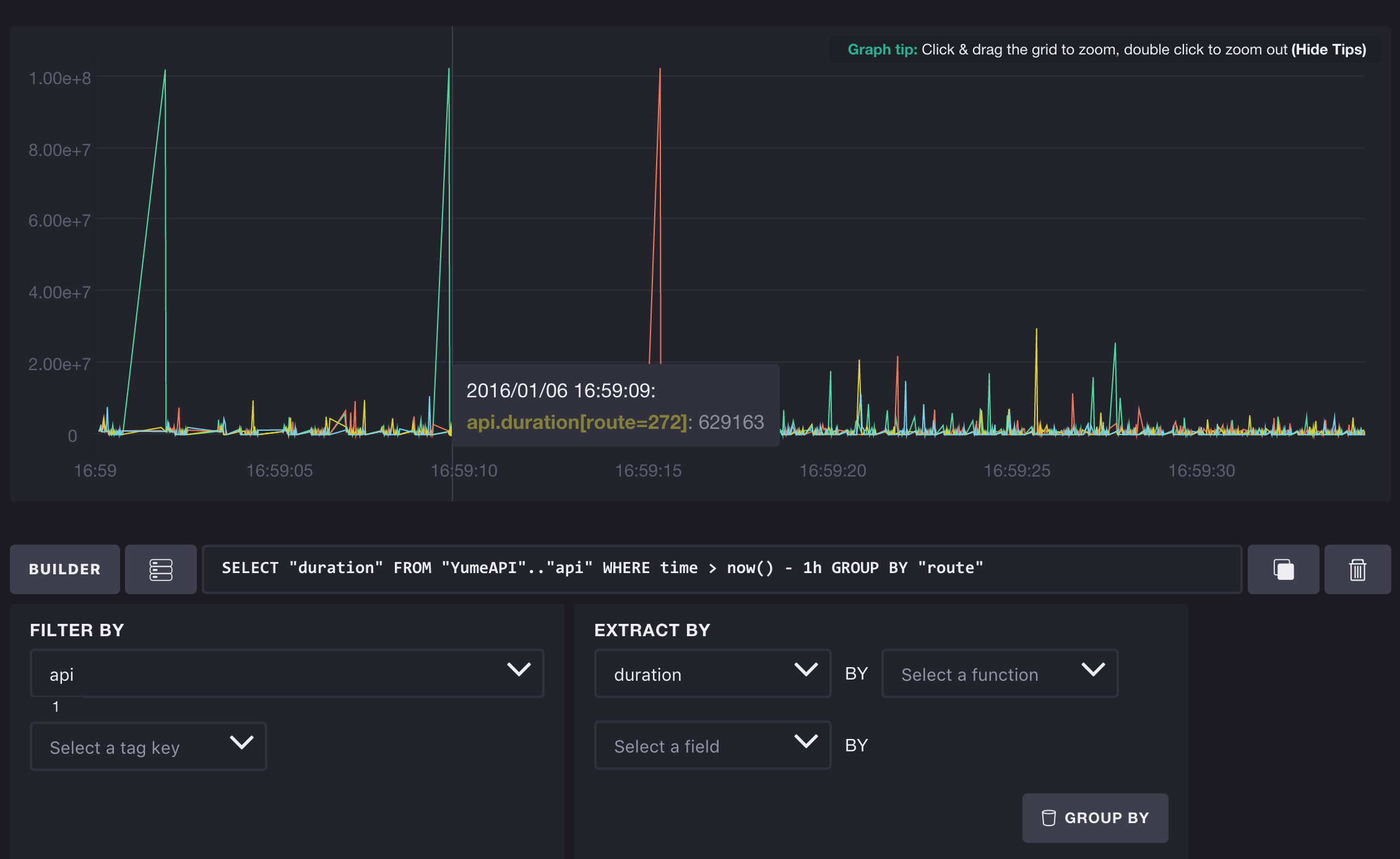
RP & CQ
1 | SHOW RETENTION POLICIES ON "telegraf" |
1 | SHOW CONTINUOUS QUERIES |
其他注意事項
Ram 數量:依照 series 基數,基數約1000萬左右會有 OOM failures(加 RAM 無解)
series 基數:DB 內所有 series 量。(2 Tags,每個 Tag 1000 可能,基數為 1M)
storeage 是設計 for SSD
hh & wal & data 目錄要放在不同儲存設備#當系統有很重的寫入工作時會有顯著的優化
術語
Point:相當於資料庫一筆 Record。由 Name, Tags, Fields組成
Name(Measurement):有點像 Table Name 的角色,想成說不能用 join,你的某組資料都只會寫到這個 table,所以也只能從這個 table query 出來。
Tags:相當於 DB 搜尋條件。以 go 來看的型態是 map[string]string。且具有 index 特性。
Fields:相當於要 Query 出來的數值。以 go 來看的型態是 map[string]interface{}。是主要要觀察的東西。
其他教學
Design Insights and Tradeoffs in InfluxDB
InfluxDB Clustering Design – neither strictly CP or AP
Continuous Queries
Authentication and Authorization
Data Exploration
Downsampling and Data Retention
Database Management
Time Series
Time Series Storage
State of the State Part III
Slide
Paul Dix, InfluxDB // Open-Source Time Series Database
Devoxx france 2015 influxdb
Video
InfluxDB Videos
The Distributed Database Internals of InfluxDB- Paul Dix
Paul Dix: Time Series Data with InfluxDB
GothamGo 2015: Go Highlights from the New InfluxDB Storage Engine by Paul Dix